
I Built a World Cup Experiment to Keep Receipts on My Predictions (And you should try it too!)
Picking winners is the easy part. The Calibration Cup is a public test of whether the confidence behind each pick was worth anything.

The World Cup starts today, and for the next five weeks a very large number of people are going to sound certain about football. Some of them have watched every qualifier. Most of them have watched almost none. It does not seem to matter much either way. The tournament hands everyone a reason to believe they can see what is coming, whether the reason is a single brilliant player, an old grudge against a rival, a half-remembered run from four years ago, or a theory about Belgium that arrived sometime around the second glass of wine. Confidence is the one thing nobody at a World Cup is ever short of.
What tends to vanish is any record of how sure people were before they found out. Once a match ends, the result quietly rewrites the prediction that came before it. An upset nobody saw coming becomes the thing you “had a feeling about.” A favorite who crashes out becomes a team you “never trusted anyway.” The confident wrong call softens into a shrug about how football is unpredictable, which is true, and also a very convenient place to hide. None of this is dishonest exactly. It is just how people protect the story of their own judgment. The cost is that the most interesting number in any prediction, the amount of confidence it actually deserved, is usually gone before anyone can look at it.
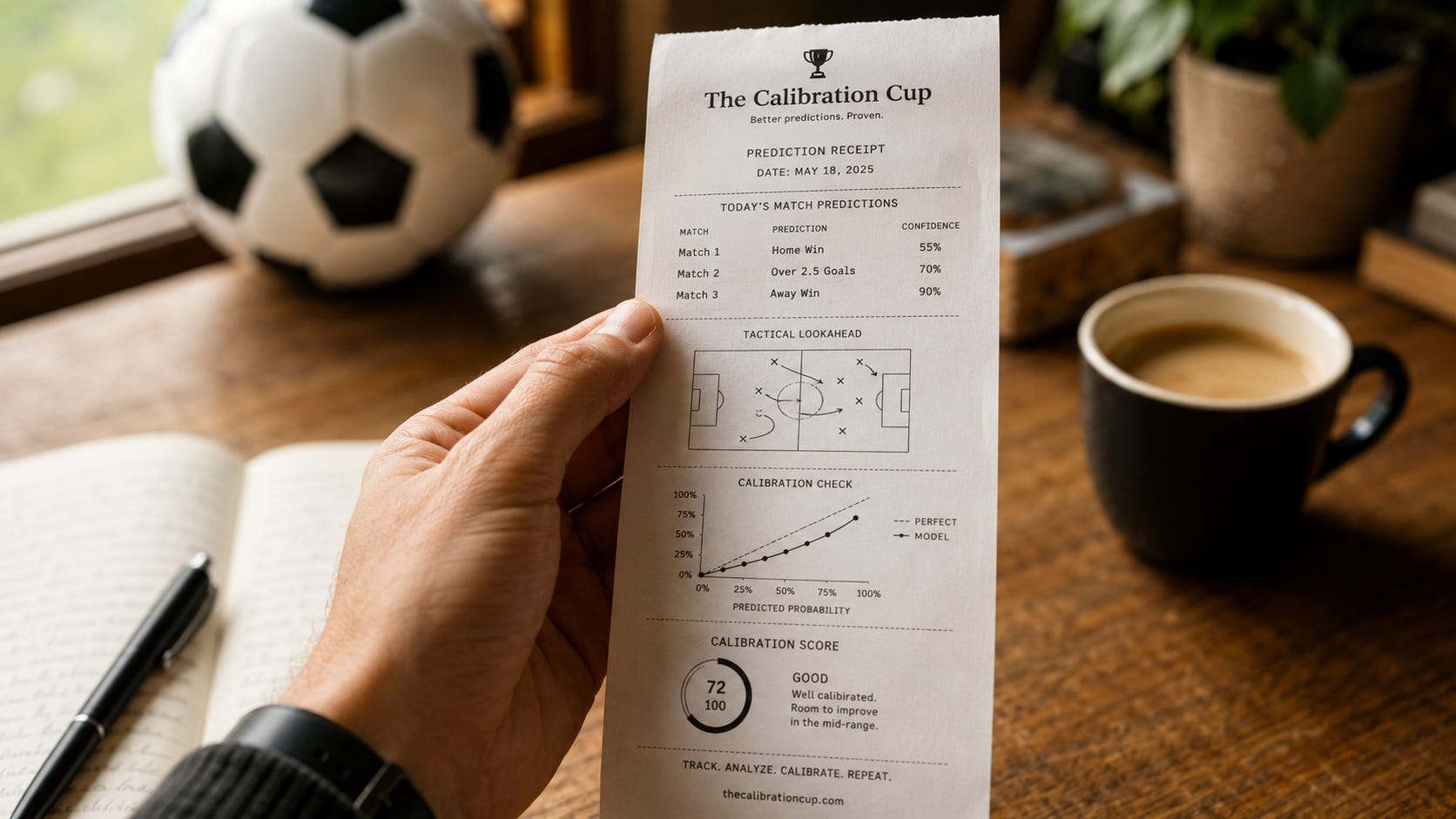
The Calibration Cup is my attempt to keep that number on the table. Before each match I make a pick and attach a probability to it, somewhere between a coin toss and near-certainty, and I publish it before kickoff. When the result lands, the pick gets scored against what happened, and so does the confidence. A cautious miss costs less than a reckless one. A lucky guess earns less than a call I had good reason to make.

How the scoring works
The scoring uses a method called the Brier score, which has been around since a meteorologist named Glenn Brier proposed it in 1950 to grade weather forecasts. The idea is simple enough to do in your head. Take the probability you assigned, subtract what happened (one if your pick came true, zero if it did not), and square the result. Say you are 70 percent sure and you are right, and you score 0.09, which is good. Say you are 90 percent sure and you are wrong, and you score 0.81, which is the kind of number that should make you wince.
Brier = (confidence − outcome)²
outcome = 1 if your pick was correct, 0 if it was not · confidence as a decimal (65% → 0.65)
Lower is better, zero is perfect, and the line worth remembering is 0.25. That is the score you would get by shrugging and saying 50 percent about everything, so anything worse than 0.25 means your confidence was making your predictions less useful than a coin flip would have been. You were not just wrong. You were sure, and wrong, which is the expensive way to be wrong. High confidence is cheap to type and expensive to defend, and the World Cup is very good at collecting on it.
Why I am really doing this
By now it may be clear that football is the occasion here more than the subject. I spend a lot of time thinking about how people make decisions with AI, and the part that holds my attention is the moment someone reads a confident-sounding answer and decides whether to act on it. The question that almost never gets asked in that moment is how much the confidence is worth. It does not get asked because confidence has no interface. A model sounds equally fluent whether it is right or wrong, and the person on the other end rarely has any history of their own to draw on, no record of the times their certainty held up and the times it quietly fell apart.
That is also, in a simplified way, one of the central problems with AI. A system can produce an answer, a ranking, a recommendation, or a risk score, but the useful question is not only whether the output is right. It is whether the confidence around that output is calibrated enough to trust. A model that is uncertain and says so can still be useful. A model that is wrong while sounding certain is dangerous in a much quieter way.
The World Cup is one of the few settings where that record gets built in public and cannot be argued away. In five weeks the results exist. Either Mexico won or they were held. Either I said 80 percent or I said 55. There is no retelling that turns a confident miss into wisdom, because the number I wrote down is still sitting there next to the score. Most of the decisions that carry real weight, the hiring call, the strategy bet, the choice to trust a system’s output, never give you that kind of clean feedback. Practicing somewhere that does is how you start to feel the difference between believing something strongly and having earned the right to. Do it long enough and your stated confidence begins to track your real accuracy, which is the whole definition of being calibrated, and one of the most quietly valuable habits a person or an organization can build.
So that is the experiment. I will log my picks before each round, score them when the results come in, and write about what the numbers say, including the ones I would rather they did not. If you want to play along, you can make your own predictions at the Cup and watch your calibration take shape next to mine. The aim is to find out what my confidence is worth while the stakes are low, so the habit is already in place the next time the stakes are not.